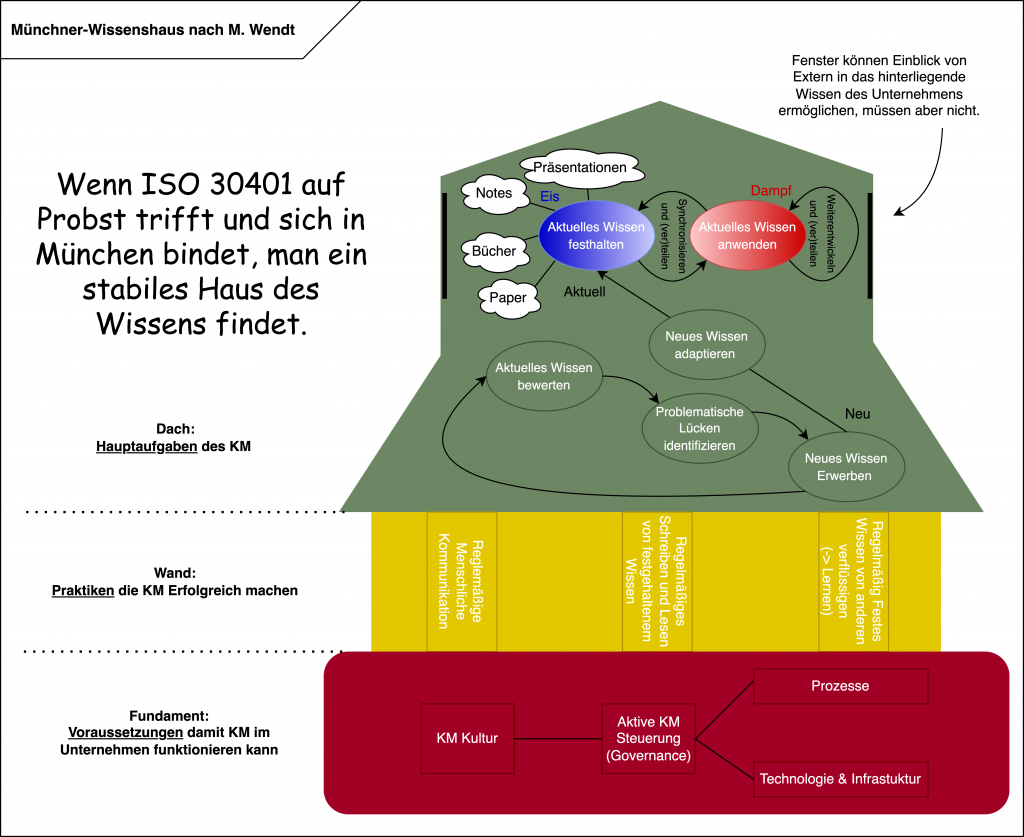
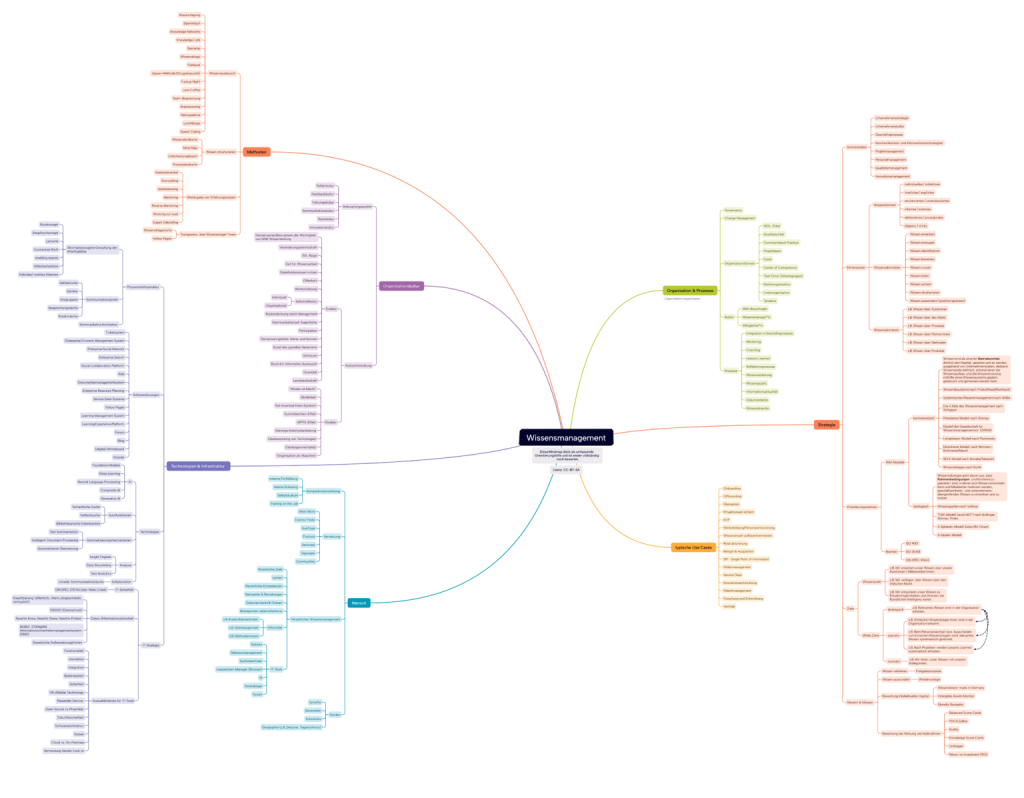
Ja, ein „altes“ Thema. Aber doch auch ein immer aktuelles und nachgefragtes. Im vergangenen Sommersemester hat Nils-Hagen Staudt, einer der Studenten in meiner Lehrveranstaltung „Wissensmanagement-Modelle und -Strategien“ an der Dualen Hochschule Baden-Württemberg, dieses Thema in seiner Seminararbeit in Form eines Literatur Reviews aufgegriffen.
Dabei hat er für die Stichwortsuche die drei Datenbanken Science Direct, Emerald Insight und IEEE Xplorer nach den Stichwörtern „Knowledge Management“ und „Success factors“ in unterschiedlicher Kombination durchsucht. Die initiale Suche ergab 39 Treffer über alle Datenbanken hinweg; 26 Einträge wurden dann ausgeschlossen, weil sich auf eine spezifische Industrie, einen spezifischen Fachbereich oder ein spezifisches Land bezogen bzw. nicht das geforderte Themengebiet trafen. Somit ergab sich eine finale Anzahl von 13 Studien, welche ausschließlich aus Literatur Reviews und Case Studies bestanden und die Erfolgsfaktoren im Wissensmanagement behandelten.
Und dies ist das Ergebnis – herzlichen Dank, Nils!
Abbildung von Nils-Hagen Staudt