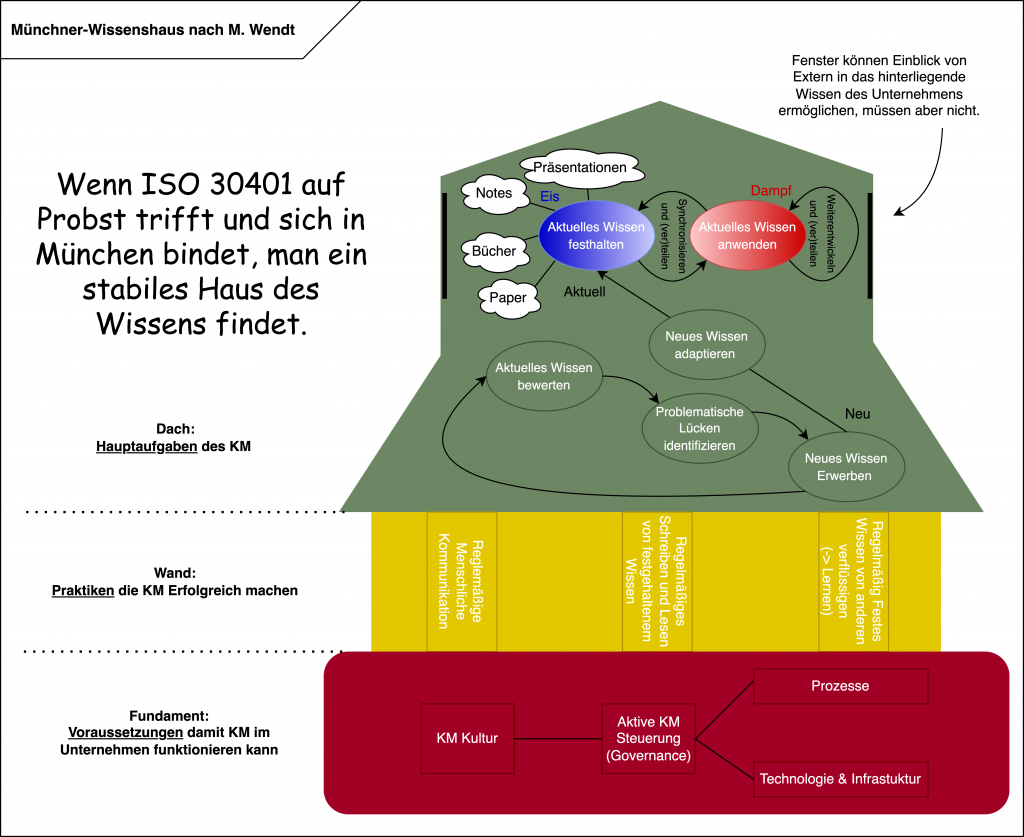
Das Münchner Haus des Wissens
Wie im letzten Blogpost bereits berichtet, erstellen die Studierenden meiner Lehrveranstaltung Wissensmanagement-Modelle und -Strategien am Center for Advanced Studies der Dualen Hochschule Baden-Württemberg (DHBW) ein kurzes Erklärvideo oder ein Icon/ eine Visualisierung zu einem Konzept aus dem Wissensmanagement.
Maximilian Wendt ist dabei kreativ übers Ziel hinausgeschossen und hat anstelle einer einfachen Visualisierung gleich ein Modell für Wissensmanagement erstellt: sein Münchner Haus des Wissens (München, weil sich im oberen Stockwerk Anklänge an das Münchner Modell nach Reinmann finden). Andere Inspirationsquellen von Max finden sich im kleinen einleitenden Reim.
Auch dieses wunderbare Arbeitsergebnis dieser kleinen Studienaufgabe wollte ich euch nicht vorenthalten. Ich finde es sehr inspirierend. Vielen Dank, Max!