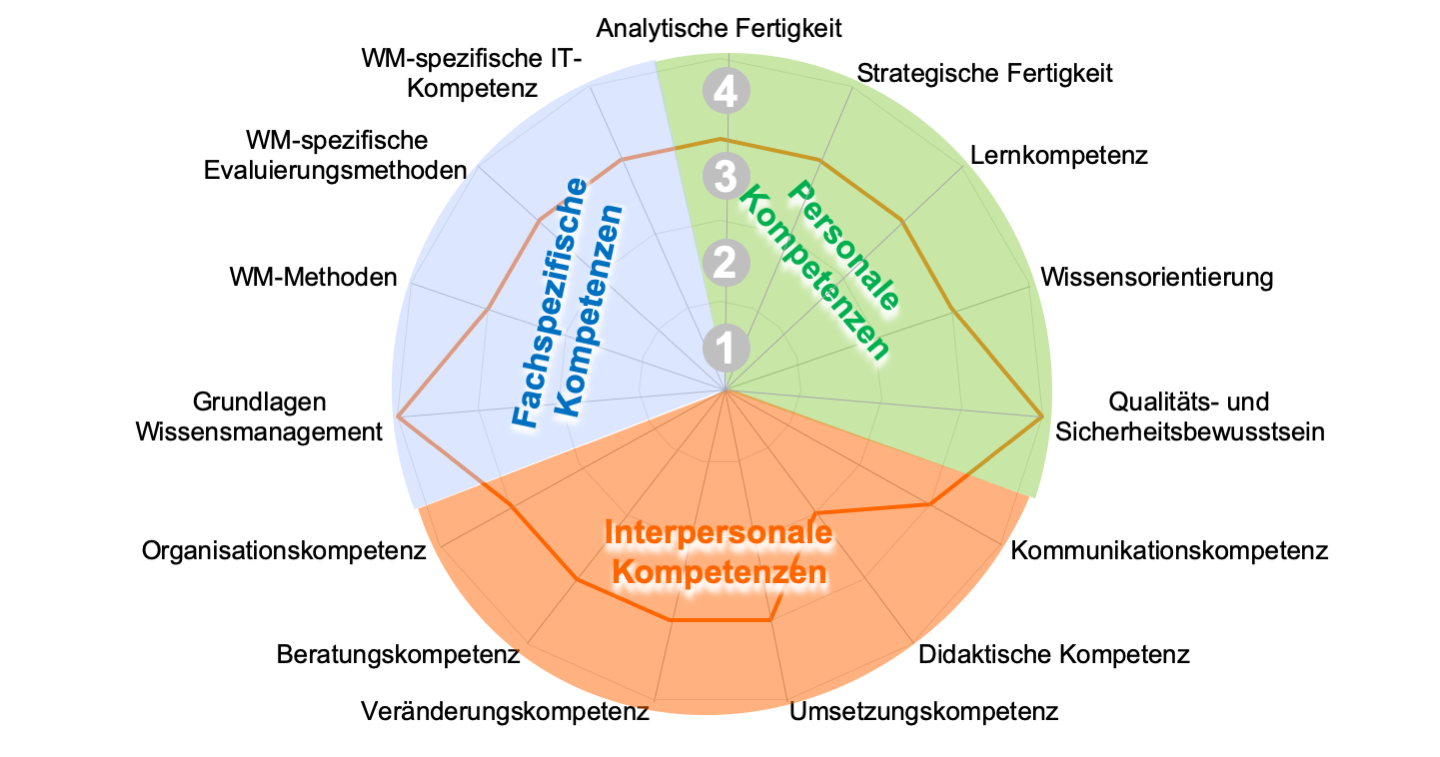
Workshop zu Kompetenzprofilen im Wissensmanagement

Am 25. Februar von 17 bis 19 Uhr biete ich gemeinsam mit Angelika Mittelmann, Sabine Wax und Ute John einen offenen Online-Workshop zur Entwicklung von Kompetenzprofilen im Wissensmanagement an. Dabei nutzen wir den von Angelika und mir entwickelten und gemeinsam mit Ute und Sabine weiterentwickelten GfWM Kompetenzkatalog.
Im Workshop werden wir in kleinen Arbeitsgruppen konkret Profile für Personae, also fiktive Personen, mit Rollen im Wissensmanagement erarbeiten. Diese Personae könnt ihr selbst mitbringen oder auch eine von uns vorgeschlagene nutzen. Durch die konkrete Anwendung werdet ihr den Kompetenzkatalog und dessen praktische Anwendung intensiv kennenlernen. Und wir erhalten von euch wertvolle Rückmeldung zum Katalog, aber auch zu Berufsbildern und Anforderungen im weiten Feld des Wissensmanagement.
Der Workshop ist kostenfrei. Bei Interesse bitte einfach bei mir melden!
Als kleine Vorbereitung könnt ihr euch mithilfe von ein paar knappen Erklärvideos schon einmal in den Kompetenzkatalog ‚eindenken‘ – müsst ihr aber nicht.
Wir freuen uns auf eine intensive Beschäftigung und Auseinandersetzung mit ‚Kompetenzen für Wissensmanagement‘.



